Red Pajama 2: The Public Dataset With a Whopping 30 Trillion Tokens

By A Mystery Man Writer
Together, the developer, claims it is the largest public dataset specifically for language model pre-training

RedPajama-Data-v2: An open dataset with 30 trillion tokens for training large language models

RedPajama Project: An Open-Source Initiative to Democratizing LLMs - KDnuggets

RedPajama Reproducing LLaMA🦙 Dataset on 1.2 Trillion Tokens, by Angelina Yang

OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models

Shamane Siri, PhD on LinkedIn: RedPajama-Data-v2: an Open Dataset with 30 Trillion Tokens for Training…
Total Licensing Spring 24 by Total Licensing - Issuu

Integrated AI: The sky is comforting (2023 AI retrospective) – Dr Alan D. Thompson – Life Architect
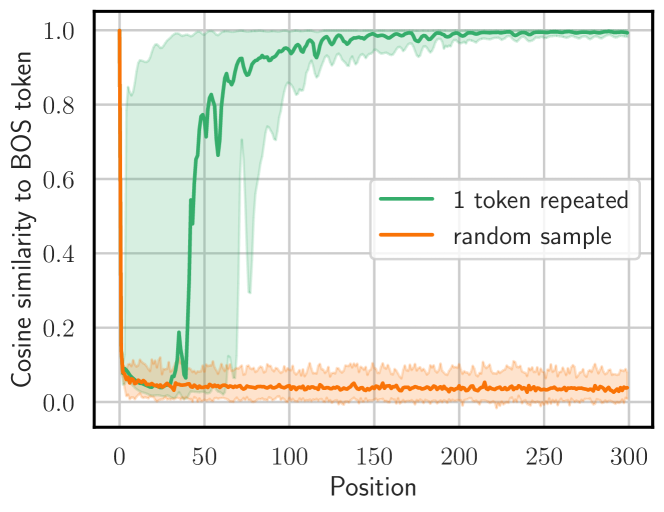
2311.17035] Scalable Extraction of Training Data from (Production) Language Models

RedPajama Reproducing LLaMA🦙 Dataset on 1.2 Trillion Tokens, by Angelina Yang

RedPajama-Data-v2: An open dataset with 30 trillion tokens for training large language models

RedPajama's Giant 30T Token Dataset Shows that Data is the Next Frontier in LLMs





- Best Deal for Fldy Mens Lingerie Nightwear Gay Sissy Satin Lace Bra

- MYLA STRAPLESS DRESS (SPICED ORANGE) – Thread Rentals

- Women's Lee European Collection Factory Flare Overall in Vibrant Blues
- Embroidered Bra Underwire Bras Underwire Bra Embroidered Lace - Women's Lace Front - Aliexpress

- SHEKINI Bralette Lace Women's Halterneck Bra Padded Longline Bra

