Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

By A Mystery Man Writer
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai
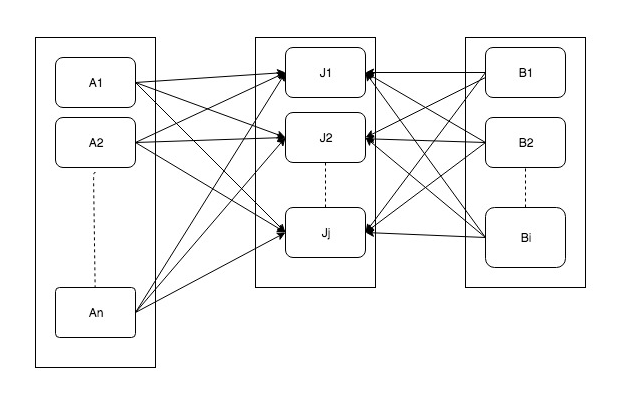
Performance Optimization of Spark-SQL

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

Kiran Sreekumar on LinkedIn: #databricks #spark #performanceoptimization
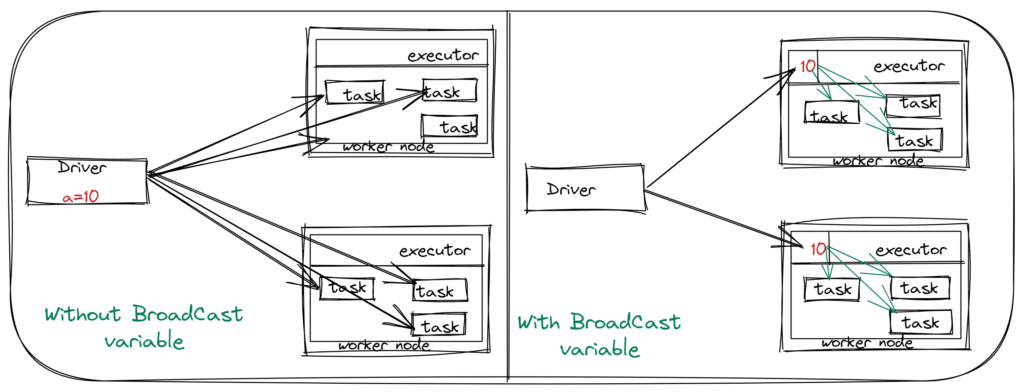
Best Practices and Spark optimization Tips for Data engineers - StatusNeo

Optimizing Snowflake Queries: Boosting Performance - Beyond the Horizon

Spark performance optimization Part1 How to do performance optimization in spark
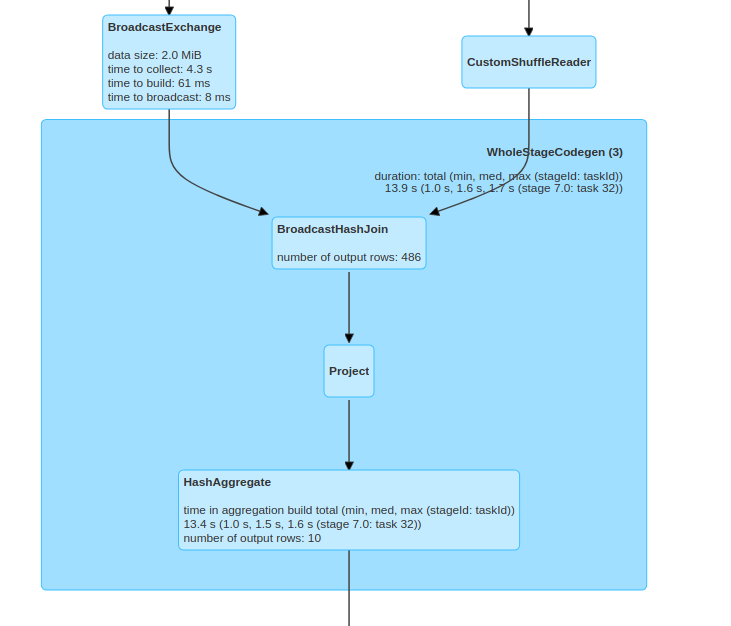
Spark 3.0: First hands-on approach with Adaptive Query Execution (Part 2)

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering

Optimizing Databricks Workloads: Harness the power of Apache Spark in Azure and maximize the performance of modern big data workloads: Kala, Anirudh, Bhatnagar, Anshul, Sarbahi, Sarthak: 9781801819077: : Books

Optimization of Spark Data Skew in Big Data Environment





- Blog - Fitness Tips Fit Factory Health Clubs
.png?ext=.png)
- 60cm bra - Buy 60cm bra with free shipping on AliExpress

- Buy Lili Women's Wide Leg High Elastic Waist Floral Print Crepe Palazzo Pants Regular Plus Size Online at Low Prices in India

- Gaiam Printed Yoga Mat 6mm PVC Lightweight Non-Slip

- NWOT Wealurre Seamless Invisible Bikini No Show Nylon Panties Set of 6 Sz: L
